
Avatar Generator
Virtual Human Generation: Part 1
Before we get started, below is a summary of the articles in this post-mortem. Although having full context is recommended, the subject matter explored herein covers many disciplines and can be consumed non-linearly. Feel free to jump around to whichever area interests you most:
Developing for DEI
Regional Template System
Standards
Systems Summary
Designing for Impatience
Design Artifacts
Avatar Samples
Personal Contributions
Executive Summary
Product Vision: VR users in the same conversation scene as mobile (iPhone X or later).
Explanation: In this example the mobile user is programmatically placed in the (circular) conversation layout. The mobile user is seeing a POV virtual camera stream of the VR avatars from the center point between the iOS user’s (avatar) eyes. Rotating the iPhone also rotates the virtual camera and the avatar “portal” itself, allowing the ability to look at others depending on who is speaking. The mobile user can choose to represent themselves as either an ARKit-driven avatar (sending blendshape values for articulating the face, alongside the voice stream) or as a typical video chat rectangle (not pictured).
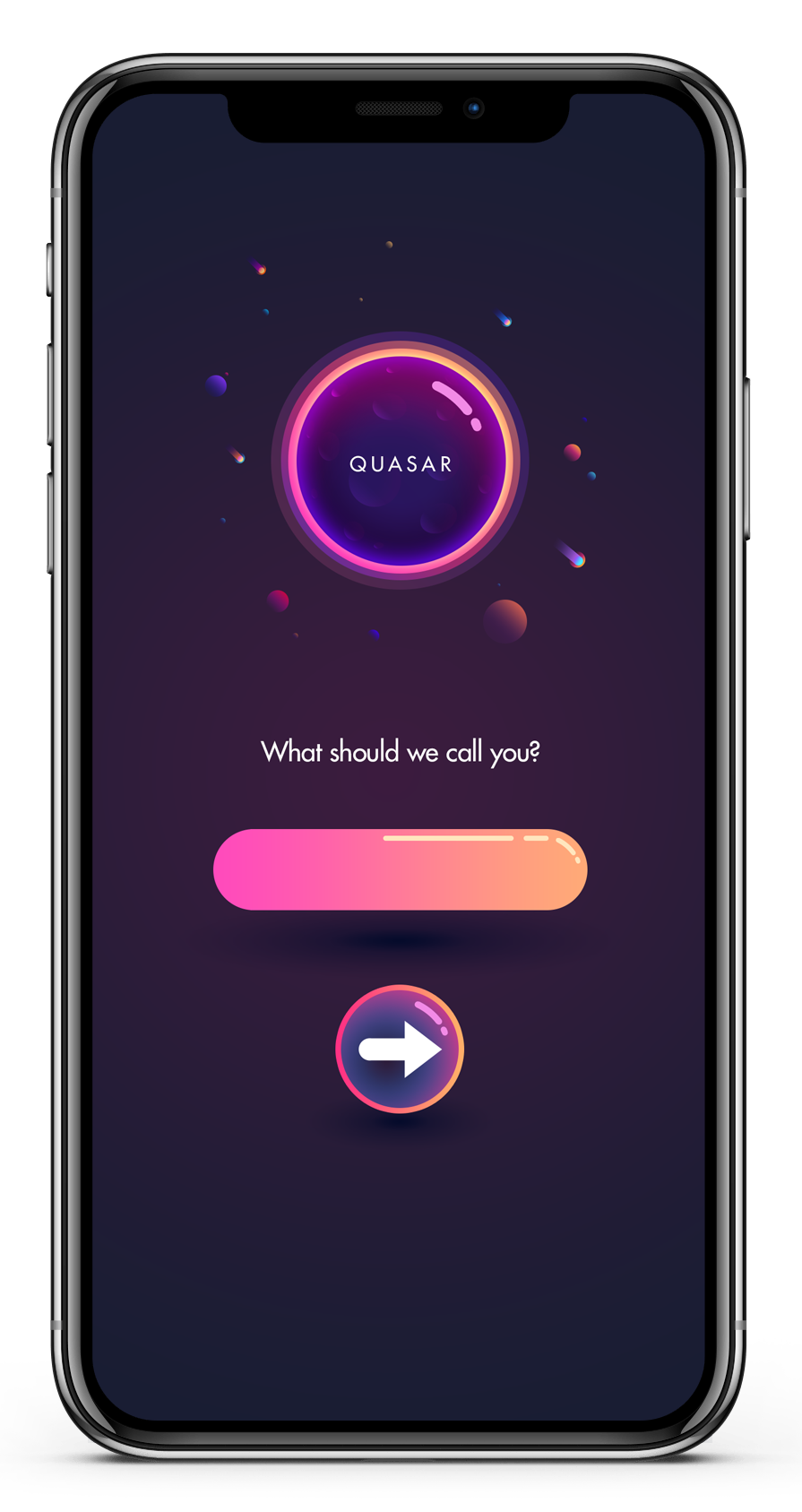
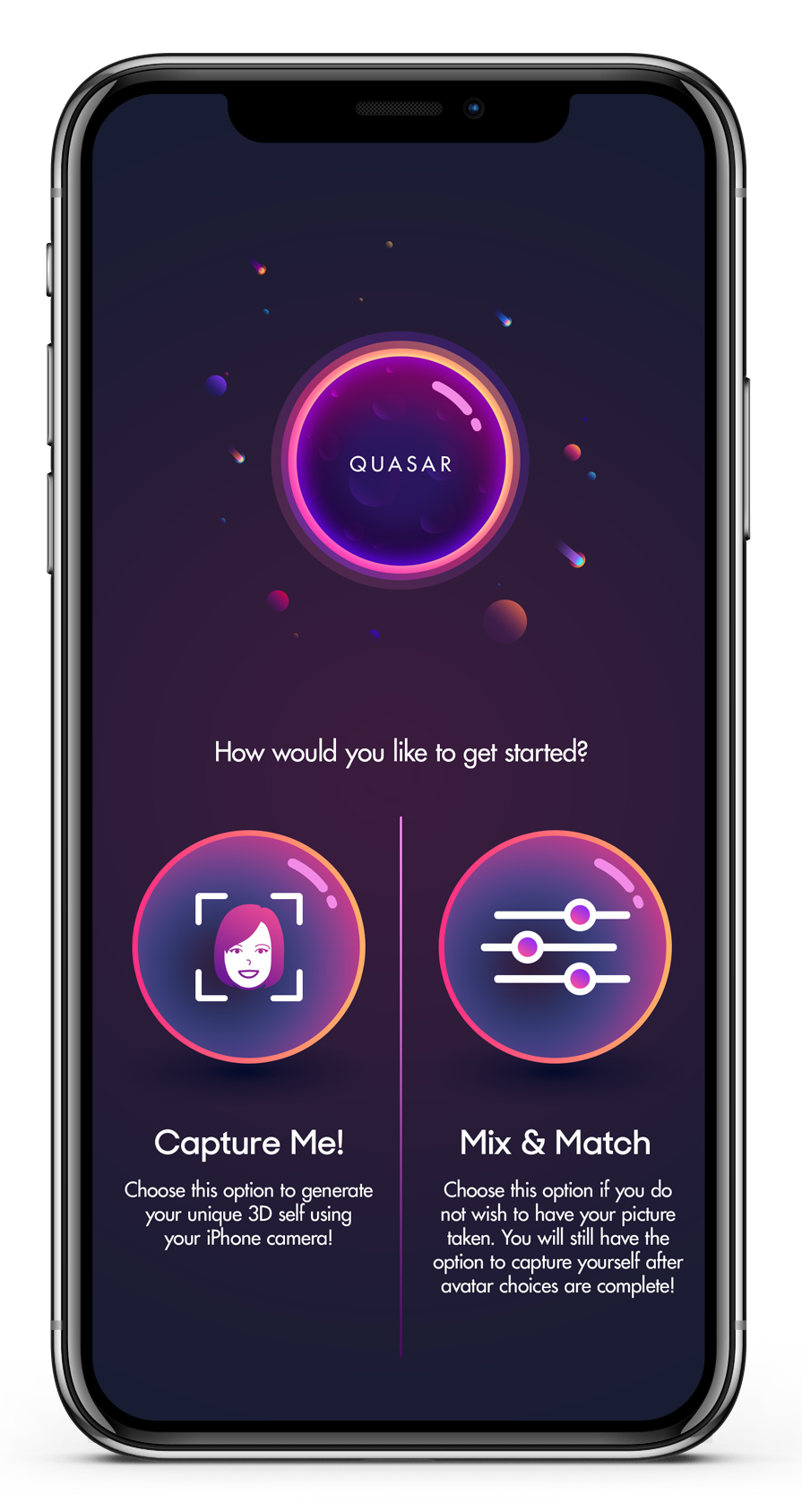



So, what is Quasar?
Quasar is a cutting-edge procedural avatar creation application built for use with the Pluto VR client — Quasar is unique in that it allows the user to capture the shape and color of the surface of their face, which then serves as the input to Quasar’s procedural generation systems to create and export a truly unique-to-the-user avatar for use in spatial conversation environments.
Why make Quasar?
With the advent of Covid19 the need for a spatial communication service has become more acutely pronounced than ever before in human history; lockdowns have become a ubiquitous part of our lives, and so too has our need for personal and professional communication to migrate towards virtual platforms (e.g. Zoom, Skype, Teams, etc.).
These virtual communication applications have certainly made lockdown life more palatable, making it both easier to keep in touch with loved ones and also continue conducting business around the world — but at the same time you would be hard pressed to find someone who doesn’t agree with the statement that much has been lost in translation with these methods.
This is to be expected — after all, these applications take the uniquely human experience of a (usually) stereoscopic face-to-face conversation and flatten, distort and wrangle it onto the screen of a device which has no internal definition of where the user is in 3D space relative to the other conversant, or vice versa.*
That said, long before Covid19 arrived, the mission for Quasar was already in place — we were going to remove the barrier of physical distance which is, and always has been, standing in the way of an intimately and collaboratively connected global human species.
* Without this internal definition it is not possible to look each other in the eyes. It’s a sad thought — of the hundreds of millions of virtual calls to have taken place over the past 20+ years, from coworkers and teammates, to friends and intimate partners — virtually none of them were able to look each other in the eyes at the same time (see this illustration). Much has been lost, but this is starting to change in some interesting ways — most notably Facetime programmatically ‘adjusts’ where the conversant’s eyes are looking.
Imagining the Possibilities
Consider for a moment, a world in which the place you call home is determined not by the location of job prospects in your field of work, but rather the location of your loved ones. Or how about waking up anywhere in the world, knowing you can ‘dial in’ to a shared virtual location which feels like a physical location? This is not far off from the concept of teleportation — and all without the risk of reassembling your biological matter in the incorrect sequence!
Having this pseudo-teleportation ability would likely reconfigure our lives to be more congruent with our hierarchy of needs — something we all strive for but so rarely achieve for any significant length of time. Usually our most enriching life-moments are confined to pre-packaged windows of time, often around the holidays or the birthday of a loved one, and if we’re lucky, some measure of self-actualization in our professional sphere. Not exactly an ideal life-structure for most people.
If such a ‘teleportation service’ were to achieve mass adoption, we would no doubt see a decongestion of the ever-densening metropolitan areas of the world, reduced housing prices, traffic, carbon emissions, reductions in large scale farming, and much more. Not only that, we would be able to seamlessly discover and collaborate with individuals from around the world on the projects which matter to us most, as if we were in the same room. Such a service would push the needle of global progress towards democratizing the very concept of human opportunity — and if shepherded effectively, it actually would make the world a better place, as cliché as that sounds. It’s true.
Envisioning this future kept myself and the team motivated day-in and day-out. It instilled in us the discipline needed to push through the innumerable challenges of hardware immaturity, resource limitations, and most of all, the mind-melting task of designing and developing an interoperable avatar system for the future of global communication.
Let’s work on our vocabulary!
Before diving in deeper, it is a good idea to come to a shared understanding of the terminology used throughout this series of articles:
What is a Spatial communication service?
Spatial generally refers to some sensory input which is experienced in all 3 dimensions (rather than the typical 2 dimensions with which we’re most familiar in digital settings)
Spatially-equipped consumer devices generally focus on spatialized audio and visuals:
Spatial visuals are experienced with the help of stereoscopic displays (be it AR glasses or a VR HMD) to communicate depth — i.e. the 3rd dimension; these devices also serve to track and transmit the movement of the user’s head/hands/body/etc in a 3D tracking volume
Spatial audio is generally experienced by anchoring the location of an audio source in 3D space which is always relative to the user’s location and movements — e.g. When you turn your head, the audio becomes more pronounced based on which ear is closer to the virtual audio source, just like real life
How does Spatial differ from Virtual?
Virtual experiences can be spatial or non-spatial — a Facetime call is a virtual experience, but it is not a spatial experience, as it is experienced by the user as a 2D pixel grid on a screen *
Spatial experiences, for our intents and purposes, are also a virtual experience — but one which has an internal framework for understanding how space affects our sensory perceptions and works towards replicating that understanding in the virtual experience
* A pseudo-spatial implementation is possible with a single 2D display — i.e. the iPhone’s ‘location awareness’ makes it possible to use the screen as a moveable ‘window’, or viewfinder, to look into a 3D virtual world in which there is object permanence — i.e. the user may move the viewfinder (phone screen) around a virtual object as if that object were in the same physical room as the phone; but, turn the viewfinder to look away from the object and it naturally gets occluded by the physical world around the phone screen, and when you rotate back to look at the object again — it has not moved from its original location in the physical room which you occupy.
What does immersive spatial communication mean?
Well, I should preface this by saying the term “Shared Presence” is typically used to talk about [social] immersion in virtual environments. If you were to Google “Shared Presence definition” you would probably find something along the lines of “Shared Presence is the feeling of presence with others in a virtual environment”. This is not a particularly useful definition for understanding the concept, so I’d like to offer the following statement [which reflects my subjective experiences in virtual environments] as an exercise:
“An immersive virtual experience is one in which the user forgets they are participating in a virtual experience.”
Assuming this is the signal rather than noise — how do we go about forgetting something?
Well, how does this same concept present itself in the physical world? When do we forget we’re doing something, and instead, are fully engaged in the task at hand? As humans we find ourselves immersed in all sorts of activities — reading, writing, speaking, listening, running, painting, coding, etc. — but these activities are not immediately immersive, quite the opposite.
At one point or another, in most of our lives, we have learned how to read — some of us had an easier time mastering it more than others, but there was always a period of learning, failure, and acclimation, prior to being able to fully immerse ourselves in the activity; a new reader stopping at each syllable, sounding it out, and then assembling the sentence’s meaning after much thought and consideration is not exactly an immersive reading experience.
The main point I am trying to make here is that immersion has its foundations in familiarity and consistency (which is something I have contended before, in the Let’s Get Physical: Part 2 article). Without those two tenants, the human mind must use part of its cognition capacity for translating unfamiliar experiences into appropriate, learned, responses. In our scenario this may present itself as someone trying to interpret an individual’s meaning or intent when they are lacking visual information which is not communicated in the same manner as previous, physical, experiences.
Until we’ve spent enough time getting acclimated to a new communication experience, our brain is filling gaps and making affordances for these unprecedented sensations and perceptions. And if we’re hoping to achieve mass adoption of such a communication service, we should design it in such a way that any user is able to hop in and immediately reap significant value from the experience, regardless of how much time they have spent in spatial environments.
So, how does this concept relate to virtual conversations?
Well, we need to reproduce, or mimic as closely as possible, the previously learned experience of talking face to face with others — we need to ensure nothing is lost in translation — preserving as much familiarity and consistency as possible. A relatively simple plan in theory, but in practice this goal must be continuously balanced with the current state of input hardware, computational resources, and ubiquity (or lack thereof) of compatible devices.
What about digital-only communication enhancements?
It stands to reason a mature spatial communication service will supersede face-to-face communication — after all, the virtual world is untethered from physical limitations, so there will always be more possibilities in the virtual.
For example, a virtual whiteboard which allows you to create an infinity-canvas which can be scrolled and scribed indefinitely in all directions with the ability to slice and export any number of variations of the data in the canvas — these types of virtual enhancements aren’t really possible in the physical world.
This digital advantage will naturally result in a disadvantage to real life face-to-face communication — but I believe it is mostly on the periphery of the face-to-face experience. That face-to-face experience has been evolving alongside our own DNA (and subsequent brain structures related to social behaviors) for 200,000+ years — we are jacked into a nervous system of sensory inputs which has evolved to be an as-perfect-as-possible system for evaluating any number of attributes which makeup a human being:
Is this person trustworthy?
Is this person being sarcastic?
Is this person compassionate?
Is this person joking?
Is this person dangerous?
Is this person ‘part of my tribe’?
etc.
Any sufficiently advanced spatial communication service will ensure these evaluations can be made just as accurately as a real-world conversation. On a long enough timeline, I imagine AI models may be able to help us with these evaluations, especially for those of us who may have autistic qualities which make it more difficult to understand another person’s intent. That said, until we have those AI models for evaluating intent, we must make these evaluations ourselves from any number of sensory clues — posture/body language, voice intonation/inflection, eye contact, micro/macro expressions, etc.
Of course, this is a tall order to reproduce all of these sensory clues — virtual realism has always been rife with inconsistencies when compared to the physical world — and most especially when rendering humans. Most people can intuitively recognize when something is a bit “off” with a virtual (rendered) human — eye saccades, sticky-lips, saliva, eye water, pore stretching, skin oil, sweat, the list goes on and on — inconsistencies with any of these subtle details will ultimately conspire together to pull us ‘out’ of the illusion. This is the great gamble of virtual realism — or more accurately, the Uncanny Valley.
The Uncanny Valley

In short — the Uncanny Valley is the tendency for humans to become repulsed by a virtual representation of a human as it converges closer to physical realism.
There are a multitude of theories for why this occurs (such as our lizard brain telling us this virtual human is ill with a communicable disease), and while it is helpful to understand the mechanisms at play in order to mitigate this phenomenon, the principle remains the same — the closer a virtual human toes the line of realism, the higher the propensity for the user’s suspension of disbelief to fail.
Technological Limitations
At the outset of planning Quasar, it was (and still is) clear that the consumer input hardware to faithfully reproduce valley-avoidant digital humans is not widely available, by any means. If Quasar were to take the realism path, not only were we facing the hard reality of technological limitations, but also the impossible challenge of trying to reproduce humans in such excruciating detail that it would fool our fine tuned sensory systems into believing what we’re seeing is happening in the physical world before us.
So, while absolute realism is and should be the ultimate goal in rendering humans for the purposes of shared presence, with today’s technology, in practice, it is a massive risk which could easily result in the ‘realism’ running a diametrically opposed campaign against the expressed goal of the project — immersion.
Although we’re quite a ways away from being able to reproduce digital humans indistinguishable from their real-world counterparts using consumer-grade hardware, there are a handful of non-consumer R&D projects out there which are doing utterly jaw-dropping work around this problem space. These projects usually rely upon extremely sophisticated input hardware (usually in the form of a spherical array of DSLR cameras firing in rapid sequence) and they are no doubt on the path to becoming the ultimate destination of rendering virtual humans.
Facebook Codec Avatar “Capture Sphere”
Photo courtesy of Facebook
Projects like the Facebook Codec Avatars are absolutely incredible to see — but (currently) impossible to implement en masse. New users require a 45+ minute session inside the capture sphere to collect enough data to infer appearance (either from HMD face cameras, or more recently, microphone input analysis).
Technological limitations made clear — a consumer grade spatial communication service must take a calculated position on the uncanny valley continuum; ideally just before that abrupt dip into repulsion territory.
What does that look like?
To answer this question, we initially went down Whitepaper Lane — something we got into the habit of doing very early on in the project. There are a couple whitepapers out there which did a good job of qualitatively evaluating the ideal stylization amounts for avoiding the uncanny valley — which I expected would aid users in making those interpersonal evaluations we covered above (e.g. is this person trustworthy / sarcastic / dangerous / etc.)
We used questionnaires coupled with renders or live demos of various types of stylization, and varying amounts for each of those stylization types.
Shape, Color, and Motion, are the knobs and levers:
Evaluating Shape meant increasing or decreasing the definition (surface realism) of facial features
Evaluating Color meant adjusting stylization procedures such as directional blurs and increasing or decreasing the opacity and shape of vector masks used in the photo details transfer to the avatar skin texture.
Adjusting Motion meant increasing or decreasing the maximum range of travel allowed by the FACS blendshape channels. It is possible to stylize or exaggerate facial muscle movements to maximize expressiveness.
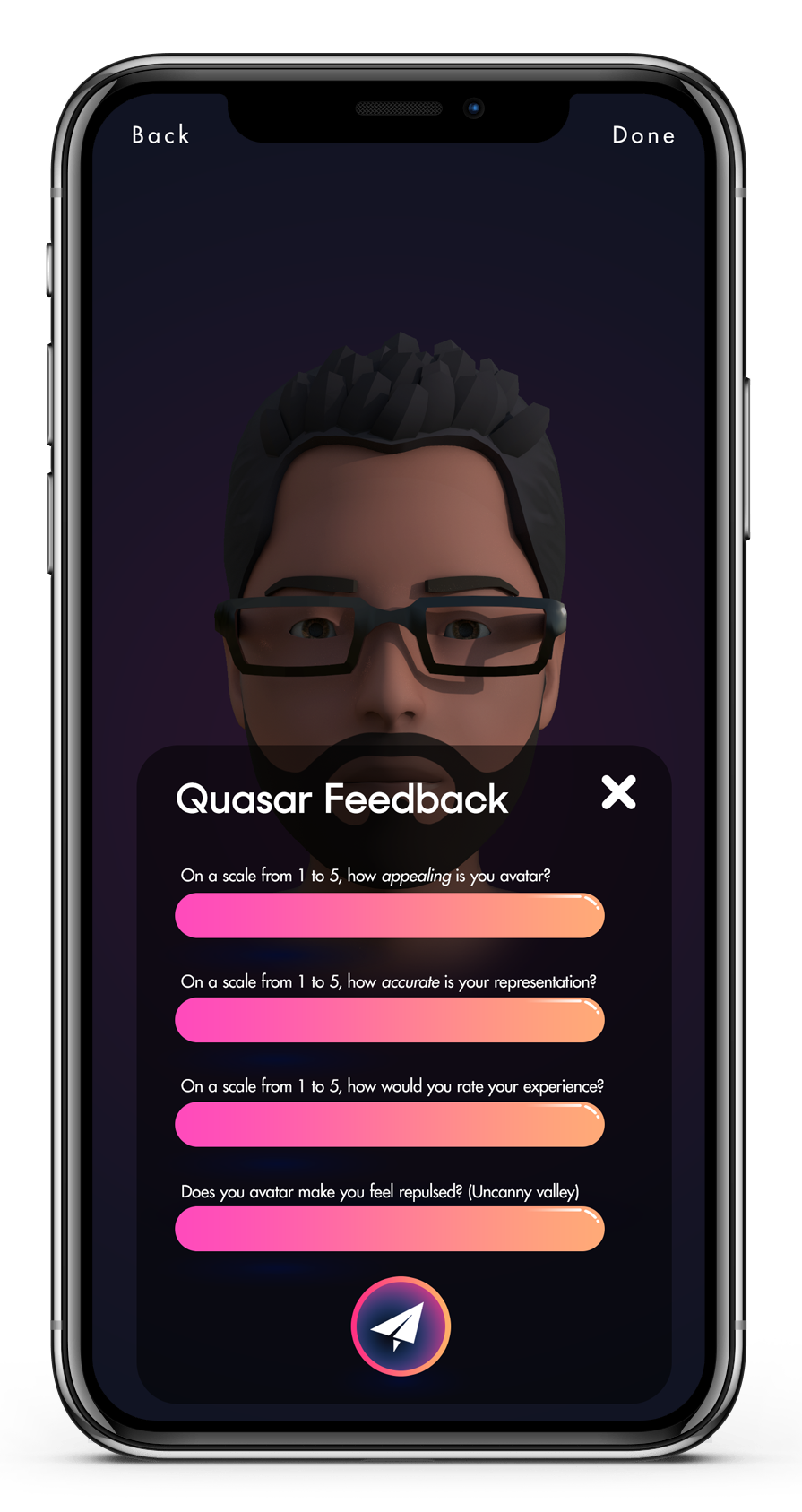
Feedback Questions:
How appealing would you rate the appearance of your avatar?
How accurate is your appearance?
Does your avatar make you feel repulsed?
Tester responses were then sorted into ‘appearance buckets’ — this was a mitigating step to ensure a high frequency of similarly-looking people (i.e. non-people of color) wouldn’t result in muting the evaluations from less-common tester appearances (i.e. people of color). This allowed us to make targeted improvements to representation coverage without compromising the experience of those users who were already pleased with their appearance.
Over the course of several iterations we zeroed in on a medium-high fidelity face surface (shape of facial features) with a lower fidelity face texture (color). Below is the end result — each of the following avatars was generated from real people — the first being myself:
Plotting the Quasar avatars on the uncanny spectrum:
This graph represents my hopes and dreams for the Quasar output — as close as possible to the valley edge using consumer-grade hardware for capture input. I believe we landed in pretty solid territory, although there were still dozens of possible improvements on the backlog when the project came to a close.

Developing for DEI
Regional Template System
Standards
Systems Summary
Designing for Impatience
Design Artifacts
Avatar Samples
Personal Contributions